











Title |
누구를 위한 DB암호화인가? | ||||
|---|---|---|---|---|---|
Author |
관리자 | Date |
2013.08.29 | Views |
187488 |
File |
|
||||
|
누구를 위한 DB 암호화인가? 저장 상태 및 운영 상태 암호화로 구분 접근필요 … DB 보안은 모두를 위한 배려
Replica HandbagsReplica Rolex Watches Replica swiss Watches DB 암호화 업계에 종사하는 필자는 가끔씩 난처한 질문을 받곤 한다. 다양한 DB 접속 서비스 중에서 DB 암호화를 통해 방어가 어려운 경로에 대한 질문이 그 중 하나다. 이때 복호 권한이 주어진 내부 사용자나, SQL Injection
에 의한 유출 시 복호화를 차단할 수 있느냐는 질문이 더해지면 그야말로 질문자의 사전 계획된(?) 의도에서 빠져 나오기 어렵다.
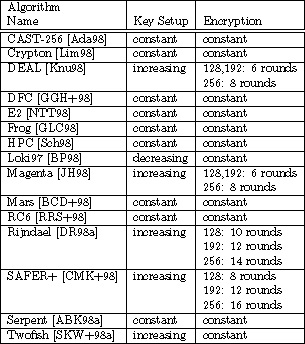
‘인가 조건을 갖춘 복호화 요청 차단 방법은 없다’고 답할 수밖에 없다. 이때면 다음과 같이 사전 계획된 답이 기다렸다는 듯이 되돌아 온다. “어차피 다 못 막는 것이라면, (DB 보안 솔루션을) 도입하는 게 의미가 있겠느냐?” DB 보안 담당자가 DB 보안 솔루션 공급업체 담당자에게 하는 하소연 섞인 질문으로 받아 들일 수 있지만, 이런 질문과 답변 속에서 데이터 보안의식의 현주소를 발견할 수 있다는 데에 의미를 두고 싶다. DB 보안은 ‘모두를 위한’ 배려‘보안’이라는 말에는 독특한 뉘앙스가 풍기는 것이 사실이다. 직접적으로 표현하면, 보수적이고 폐쇄적인 느낌과 불편함 등이다. 하지만 항공사에서 지속적인 안전훈련 실시의 이유를 한번 생각해보자. 그것은 생각하기도 싫은 만약의 경우를 대비하기 위함이다. 법-규정이라는 범위를 넘어 항공사로서 고객을 보호하려는 배려이자 사회적 약속을 지키는 일이다. 기업 또는 조직의 데이터도 충분히 보호하고 보호 받아야 하는 중요한 자원임은 새삼 강조할 필요 없다. 하지만 시스템 보안 담당자들조차도 DB 보안에 대한 관심이 느슨한 편이다. 저장 및 운영상태에 따른 보안효과, 또 누구로부터 데이터를 보호해야 하는지에 대한 관심은 생각보다 높지 않다. 그나마도 도입 과정에서 조직 내 부서 간 입장 차이에 따라 DB 보안이 뒷전으로 밀려나기까지 한다. ‘열 장정 도둑 한 명 못 막는다’는 말이 있다. 교묘하게 빈틈을 노리고 들어오면 허점이 노출될 수밖에 없다. 하지만 보안 시스템이 있는 경우와 없는 경우는 사후 조치에서도 크게 차이가 난다. DB 보안 시스템을 도입·운영함은 지속적 모니터링 시스템을 운영하고 있다는 의미이자, 피해를 줄이겠다는 준비를 하고 있음이기에 사후 처리에서도 도입한 곳과 도입하지 않은 곳, 더 나아가 관심을 둔 곳과 형식적으로 유지하는 곳과는 차이가 날 수밖에 없다. 모름지기 보안은 취약점을 지속적으로 없애는 것이 목적이고, 취약성이 높고 발생 가능성이 높은 순서대로 방비해야 한다. 설령 핀홀처럼 아주 작은 취약점 중 일부는 기술적 한계로 인해 대비책이 없을 수도 있지만, 전체적으로는 사고 발생 가능성을 크게 줄여주는 것임에는 분명하다. 필자는 이 글에서 DB 보안에 대한 최근의 기술적·사회적 이슈를 동시에 다뤄보고자 한다. DB 암호화에서 알고리즘 및 키 길이가 성능에 주는 영향AES, ARIA, SEED 같은 대칭키 알고리즘에 있어서 알고리즘의 종류와 키 길이는 암/복호 성능과 직접적인 관계가 있다. 즉, 알고리즘의 구조에 따라 CPU 연산 양이 달라지며, 같은 알고리즘이라도 키 길이에 따라 라운딩 횟수가 달라지기 때문이다. <표 1> 펜티엄 시스템에서 키와 다른 텍스트 크기를 암호화할 때 바이트당 클럭 사이클 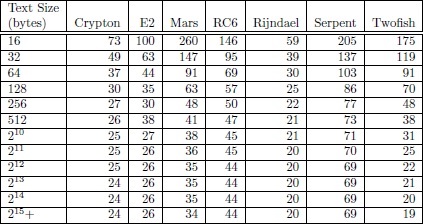 <표 2> 서로 다은 키 길이에 대한 AES 알고리즘 속도
 <표 3> 암호 모듈을 장착한 암호 솔루션(API)의 실제 작동 성능 측정(권한통제 및 I/O 부하 포함)
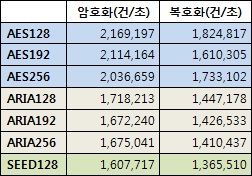 *테스트 서버 사양: 인텔 i5-2410M 2.3GHz, 2 core CPU, 메모리 1.5G, 리눅스 커널 2.6.18 64비트)
<표 3>처럼 알고리즘별로 제법 성능 차이가 나며, 키 길이에 따른 성능 차이도 있다. 그러면 이 같은 차이가 DB의 데이터를 암호화할 때에 어떠한 영향을 미치는지 알아보자. 법-규정상 암호화가 필요한 컬럼들(고유 식별번호, 카드번호, 계좌번호, 비밀번호 등)이 DB 테이블에 들어 있고, 이들 필드를 AES, ARIA 등으로 암호화하면 16바이트 길이의 바이너리 데이터로 바뀌어 저장된다. SQL 문장의 처리 과정이 복잡하고 시간이 많이 소요되며, 이 과정들 중에 한 필드의 암/복호화가 순간적으로 수행되기 때문에 알고리즘 종류에 따른 SQL의 수행시간 변화는 거의 없다고 볼 수 있다. 하지만 LOB 데이터에 대해서는 영향이 있다. 결국 한 번의 인스트럭션에 의해 많은 데이터 블록이 처리되는 파일 암호화는 알고리즘의 종류에 따라 성능 차이가 극명하게 나타난다고 할 수 있다.  <그림 1> 암호화한 쿼리 처리 과정
하드웨어 암호화와 성능암호화는 CPU 연산을 요구하기 때문에 수학 계산보다는 인스트럭션 처리에 적당한 구조의 범용 CPU 사용이 어찌 보면 최선은 아니다. 이에 따라 그 동안 암/복호화를 빠르게 처리할 수 있는 별도의 하드웨어 장치들이 고려되곤 했다. 가장 최근의 장치로는 엔비디아(NVidia)의 GPU 연산을 이용하는 CUDA 프로그램을 들 수 있다. 그러나 그러한 HW들을 이용하는 데 있어 문제점은 병목현상을 피할 방법이 마땅치 않다는 것이었다. 즉, 액셀러레이션 HW를 이용하기 위해서는 PCI 슬롯에 장착하든가 아니면 별도의 어플라이언스 형태로 네트워크로 연결해야 한다.
문제는 이 인터페이스 구간의 속도가 CPU와 메모리 사이의 속도와는 비교가 안 될 만큼 느리다는 데 있다. 이 때문에 그다지 매력적인 성능향상 방안이 되지 못했던 것이다. 하지만 최근, CPU 벤더들이 CPU 칩세트 안에 별도의 AES 구동 로직을 추가하면서 얘기는 달라졌다. AES 알고리즘 처리를 CPU 연산을 통하지 않고도 HW 로직에 흘려 보내기만 하면 되기 때문이다. 인텔이 AES-NI라는 새로운 인스트럭션 커맨드 세트를 지원하고 있으며, 오라클은 T4 CPU에 이와 같은 기능을 지원하는 ‘인크립션 인스트럭션 액셀러레이터’를 탑재했다. IBM 또한 Power7 프로세서에 인스트럭션은 없지만 ‘Cryptographic Processors’를 지원하고 있다. CPU 차원에서 하드웨어적 기능을 지원하면서 적어도 AES 알고리즘 연산을 위한 오버헤드 문제는 해결됐다. 하지만 이런 구조들이 암호화 단위가 큰 대용량 파일 암호화 또는 DB에 저장된 LOB 데이터 등의 처리성능 향상에는 큰 도움이 되겠지만, DB처럼 작은 필드 단위로 암/복호화하는 경우는 별 도움이 되지 못한다. 고작해야 16바이트 크기인 1개의 필드 암/복호화는 극히 짧은 순간인 반면, SQL 문장의 처리 과정은 상대적으로 복잡해 많은 시간이 소요된다. 이 때문에 이 같은 HW 액설러레이션 효과를 볼 수 없는 것이다. 부분 암호화 vs. 전체 암호화암/복호화 처리 부분만 보면, 부분 암호화보다는 전체 암호화 속도가 빨라야 한다. 왜냐하면 부분 암호화는 전체 암호화와 마찬가지로 한 블록의 암호화 과정을 수행하고 나서 평문 데이터와 결합/분리하는 작업이 따르기 때문이다. 하지만 DB에 저장된 필드를 암호화하는 경우에 있어서 이 암호화 컬럼이 인덱스로 만들어지고 조건검색 SQL이 수행되는 경우에는 결과가 달라질 수 있다. 이는 조건검색을 위해 DBMS의 옵티마이저가 세운 실행계획과 관련이 있기 때문이다. 부분 암호화한 것을 일반 인덱스(B-Tree Index)로 생성할 수 있으며, 이 경우는 실행 계획이 바뀌지 않는다. 다만 데이터를 암호화 하지 않고 평문으로 둔 범위 내에서의 조건 검색이 가능하다. 전체 암호화를 하는 경우는 기본적으로는 암호문을 인덱스에서 오더링하므로 색인 검색이 불가능하다. CubeOne 등 제품에 따라서는 인덱스에서 오더링을 유지할 수 있어 색인 검색이 가능하다. 그러나 이것은 어디까지나 데이터가 오더링을 유지하고 있는지에 대한 관점일 뿐이다. 오더링을 유지한다 하더라도 평문이 아니기 때문에 검색을 위해서는 데이터 변환 과정이 필요하다. 이것을 가능하게 해 주는 것이 FBI(Function Based Index)다. FBI를 이용하기 위해서는 함수를 호출해야 하는데, 자동으로 호출할 수 있게 해 주는 것이 오라클의 ‘Domain Index’라는 독특한 인덱스다. 다만 옵티마이저의 실행 계획은 바뀌는데, 암호화 이전에 비해 빠를 수도 있고 늦을 수도 있다. 정리해 보면 다음과 같다. 부분 암호화는 평문으로 남겨둬야 하는 문제 때문에 보안성은 약하지만 암호화 솔루션 적용에 따른 DB 검색성능 저하가 따르지 않을 수 있다. 또한 DBMS의 종류에 무관하게 적용할 수 있다. 즉, 어떤 종류의 DBMS에서나 동일한 결과를 기대할 수 있다. 전체 암호화는 검색 성능은 일부 제약(制約) SQL 문을 제외하면 암호화 이전과 거의 차이 없을 정도의 성능을 나타낸다. 제약 SQL은 문장 수정이 필요하지만 보안성이 매우 뛰어나다. 키 길이와 기밀성, 사용권한 통제데이터를 암호화만 하면 보안은 끝나는 것일까? 적지 않은 사람이 ‘암호화하면 유출 시 안전할 것’이라고 생각한다. 암호화의 목적은 데이터가 불법으로 유출되더라도 복호화할 수 없도록 암호화해 놓음으로써 2차 피해를 방지하는 것이다. 이를 위해서는 강력한 알고리즘(키 길이 포함), 키 기밀성과 사용권한 통제 메커니즘이 필수적이다. 어느 한 가지 요소라도 부족하게 되면 유출 사고 시 2차 피해가 불가피해 진다. <표 4> 보안을 결정하는 요소
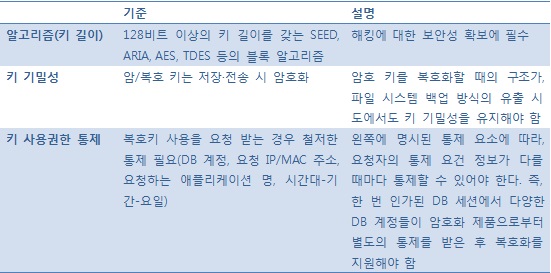 정리하자면, TDE나 파일 암호화 같은 DB 암호화 솔루션으로 구축한 경우에는 DB를 스타트할 때에만 키 사용권한 통제가 이뤄지기에 일반 DB 계정에 대한 통제는 불가능하다. 더불어 그 이후에는 DBMS의 ACL만 작동하는 경우라면, DB가 운영중인 상태에서는 암호화 이전과 다를 바 없다. 파일 백업 유틸리티를 통해 ‘dbf’ 파일을 직접 복사하는 경우를 제외한 운영중인 상태에서는 이미 모든 사용자에게 복호화 권한이 부여돼 있다는 의미다.
어떤 상태로 누구로부터 보호할까?데이터는 크게 3가지의 상태로 나눌 수 있는데, <그림 2>와 같은 저장 상태(Data at Rest), 이동 상태(Data in Motion), 사용 상태(Data in Use)로 나뉜다. 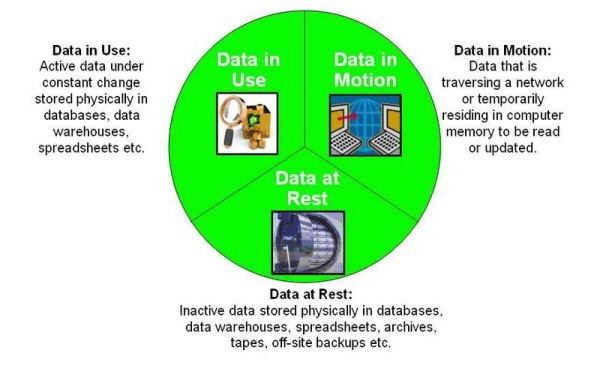 <그림 2> 데이터의 3가지 상태 (출처: Wikipedia)
위의 3가지 데이터 상태 중에서 이동 상태는 극히 일시적으로 데이터가 존재했다가 사라지는 것이지만, 저장 상태와 사용 상태는 상대적으로 아주 길게 데이터가 존재하게 된다. 자명한 얘기지만 데이터가 한 곳에 오래 있으면 있을수록 유출 위험은 가중될 수밖에 없다. 따라서 저장 상태와 사용 상태에 있는 중요 데이터가 평문 상태로 유출되지 않도록 방어할 필요가 있다.
따라서 DB 암호화는 크게 ‘저장 상태에서의 보안효과’와 ‘운영 상태의 보안효과’로 나눌 수 있다. 저장 상태 DB 암호화저장 상태의 보안효과란 암호화한 자료의 종류와 이것을 사용하는 응용 프로그램의 작동과 무관하게 OS의 기능을 이용해 디스크에 저장된 자료를 읽었을 때 암호화 상태가 유지됨을 말한다. 다시 말해 파일 시스템 백업(backup) 또는 카피 등에 의해 유출된 복사본이 안전함을 의미한다. 운영 상태 DB 암호화운영 상태의 보안효과란 암호화한 자료를 특정 응용프로그램(DBMS 등)을 이용해 사용될 때에 한해 보안을 유지함을 뜻한다. 일반적으로 PC 또는 스마트폰과 같이 개인 사용을 전제로 한 운영 조건에서는 이 두 가지를 모두 충족하기가 어렵지 않다. 단순히 디스크 암호화 또는 파일 암호화만으로도 목적하는 보안을 달성할 수 있다. 하지만 다중 사용자가 이용하는 서버에서는 이야기가 달라진다. 즉, 디스크 암호화 또는 파일 암호화를 적용한 경우는 저장 상태의 보안효과 이상은 기대할 수 없다. 왜냐하면 이 서버들은 2티어 또는 3티어 구조로 연결된 업무용 컴퓨터들과 OS 계정을 공유하는 다수의 애플리케이션 사용자들이 자료를 사용하기 때문이다. 결국 통제 대상의 세분화와 관련된 문제라는 뜻이 된다. 실제 식별할 수 있는 사용자를 통제할 수 있어야 하므로 DB 암호화는 DB 계정(DB가 인식하는 사용자)별로 통제할 수 있어야 한다. 그래야 365일 항상 ‘dbf’ 파일이 오픈된 상태로 운영되는 데이터베이스의 보안효과를 유지할 수 있다. 암호화의 기본 정의우리가 암호화를 해야 하는 목적은 ‘개인정보보호법’의 <지침 해설서> 208쪽에 나와 있다.  <그림 3> 행정안전부의 ‘개인정보 보호법령 및 지침 고시 해설서(2011년 12월 15일) 208쪽
암호화는 유출 자체를 막는 것이 아니다. 그것을 하는 DRM, DLP, DB 접근제어, ESM 같은 많은 종류의 제품들이 있지만, 만일 유출되더라도 복호화 키 없이는 복호화가 불가능하게 차단하는 것이 DB 암호화 제품의 목적이다. 따라서 이를 보장 받기 위해서는 규정에 맞는 알고리즘 사용, 저장된 키와 이 키를 평문키로 변환할 때의 기밀성 유지, 복호키 요청 시의 철저하고 세밀한 통제 메커니즘의 작동이 반드시 이루어져야 한다.
DB 암호화 제품별 장단점DB를 암호화할 수 있는 제품은 여러 유형으로 나뉜다. 가장 대표적인 제품은 데이터가 있는 곳에서 암/복호화하는 플러그인 제품과, 요청하는 곳에서 암/복호화하는 API 제품, DB 커널 레벨에서 처리하는 TDE 제품 등이 있다. 그 외에 파일 암호화 제품을 이용하는 경우도 있고, Token/PIN 등의 평문을 임의의 다른 데이터로 대체하여 저장-처리하는 방법도 있다. 이러한 제품들의 특성과 장단점에 대해서는 참고할 수 있는 자료가 이미 많이 소개됐으므로 여기서는 가장 대표적인 장단점을 알아본다. <표 5> DB 암호화 제품 형태별 장단점 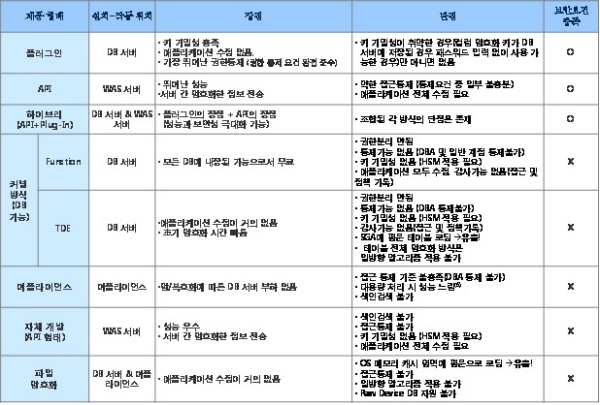 빅데이터 시대의 DB 암호화빅데이터와 보안은 어디인지 모르게 서로 어울리지 않는 것처럼 느껴진다. 빅데이터가 태동기식 간의 인식이 작용했기 때문일 것이다. 대용량 데이터에 대한 보안을 직접 거론하기는 아직 이르기 때문에 빅데이터 이슈를 몰고온 클라우드 컴퓨팅에서의 DB 보안으로 좁혀 알아보자. 일반적으로 조직 내의 시스템에 저장된 자료는 자료별로 애플리케이션(DB 또는 기타 애플리케이션) 구분이 가능하다. 또한 애플리케이션 레벨의 사용자 구분 및 그 사용자들의 소유 데이터로 구분할 수 있다. 암호화에 따른 보안성을 갖기 위해서는 이 레벨의 사용자를 인가/비인가로 설정해야 하며, 그 사용자별로 암/복호 키를 따로 작용할 수 있어야 한다. 하지만 애플리케이션 임대 서비스(ASP)나 클라우드 서비스와 같은 경우는 이렇게 암호화를 적용 하기가 거의 불가능하다. 그래서 보통 디스크 암호화 또는 파일 암호화를 걸어서 서비스하고 있는데, 딜레마는 다른 사용자(타사, 경쟁사, 또는 클라우드 관리자)가 내 자료를 볼 수 있고, 또 유출될 수 있는 문제점은 암호화 이전과 다를 바가 없다는 점이다. 이 경우의 암호화 효과는 클라우드 또는 ASP 사업자가 파일 백업 또는 복사 방법으로 데이터를 유출하려 했을 때에만 효과를 발휘할 수 있다. 결국, 이런 서비스에는 마이크로소프트 엑셀이나 파워포인트 같은 개인용 애플리케이션 자료를 올리는 것은 괜찮지만, DB와 같은 다중 사용자 서비스 기반의 애플리케이션 자료를 올리는 것은 현재로선 생각해볼 일이다. 건강한 발전을 위한 조건다시 DB 보안 분야의 현실에 대해 얘기를 나누면서 이 글을 마무리할까 한다. DB 암호화를 하려는 많은 기업 또는 기관들과 협의하다 보면, DB 암호화 목적이 만약의 유출사고에 철저히 대응하려는 것으로 인식하는 경우는 그리 높지 않다. 적지 않은 곳에서 법 규제를 준수하는 차원에서 접근한다. 공공기관은 기술적인 전문성보다는 관리형 담당자들이, 일반 기업은 대부분 보안 관련 자격증을 가진 사람들이 보안 업무를 담당한다. 하지만 아이러니하게도 보안의식이 보안 자격증과 관련 없다는 것이다. 금융권 중 일부 업종의 공통점은 운영·개발팀의 주장이 강조된 나머지 보안은 검토 항목에만 존재할 뿐 정작 제품 선정에서 주요 기준이 되지 못한다. 이 때문에 운영상태의 데이터가, 보안 수준이 매우 낮거나 전혀 없는 방식으로 DB 암호화가 구축된다. 심지어 기준에 맞는 보안성이나 기능 충족성에 여부는 무시하고 단지 가장 도입비용 부담이 낮은 제품으로 결정해 버리기도 한다. 금융권 보안사고가 끊임 없이 이어지면서 최근 분위기는 ‘사고 발생시 CEO 중징계’로 수렴되는 모습이다. 기업 차원의 피해를 넘어 기업 또는 기관의 데이터는 사회적으로 중요한 자산임을 암묵적으로 인정하기에 이르렀다는 의미다. 어느 시대건 새로운 분야의 기술이나 시장이 형성될 때, 합리적이고 보편적인 가치관의 정립되기 까지는 다양한 시각과 의견들이 존재하게 마련이다. DB 암호화의 경우도 이러한 과정들을 거쳐 왔으며, 또 현재 진행형이라고 볼 수 있다. 시간이 지남에 따라 차차 정리되겠지만, DB 암호화는 중요 정보를 보호하는 것을 목표로 하기 때문에, 꼼꼼하게 점검되지 않은 DB 암호화는 그만큼 위험에 노출될 확률이 높다. 보편 타당한 기준으로 제품을 보고, 합리적인 가격으로 구매하는 풍토가 IT 업계에도 정착돼 기업들이 건강하게 발전할 수 있었으면 하는 바람이다. |
|||||

prev  |
||
|---|---|---|
next  |